Hello, everybody. Apologies in advance for such a long post—I’ve held back introducing this for a very long time. I hope anybody finds it interesting :)
I have been following uLisp for a few months now. It has been incredibly inspiring! I can really appreciate the versatility of Lisp in general, and it was wonderful having its implementation click when learning about it. However, I found uLisp on my own journey of creation: an s-expression language for Arduino/PC called Chika.
The rationale is a system facilitating “flash once”, where as much of the platform as possible is within user programs rather than built into the language. While this precludes bare-metal native performance, it has luckily proven its own benefits.
Cheekily, a goal all along has been to exceed the speed of uLisp. Chika is able to perform (tak 18 12 6) in 9.6s, compared to uLisp’s 15.0s, on my Adafruit Feather M0; or with O3 optimisation 7.6s vs. 12.8s. This is just one example mind, echoed through many limited benchmarks.
It’s at a heavy price: no mutation, homoiconicity, closures, native REPL, macros, laziness, multi-arity, orthodox syntax, or code imports with necessity for an SD card. I don’t call it a Lisp. Chika eschews heap/GC memory, instead s-expression arguments are stacked and consumed by the native operation or program function.
This gives Chika very different memory characteristics to uLisp. While it doesn’t have to break values into linked-list cells, it does have to duplicate items in memory—however long they may be—before operating on them. Strangely it was way slower mitigating this with copy-on-write than just letting memcpy do its thing, so I chose that…
There are some perceived benefits however, with implemented: 100% pure functions and immutable memory, round-robin scheduler, inter-program messaging, native Linux support. Currently programs request an amount of RAM and have a simple life-cycle: compilation (once), entry, heartbeat, messages, halt. The scheduler ‘beats’ the heartbeat function of each program (if it exists) until halted. Programs can create MQTT-like message callback subscriptions and broadcast messages to the system. These messages are a topic string with simple wildcards and a payload item (any data type).
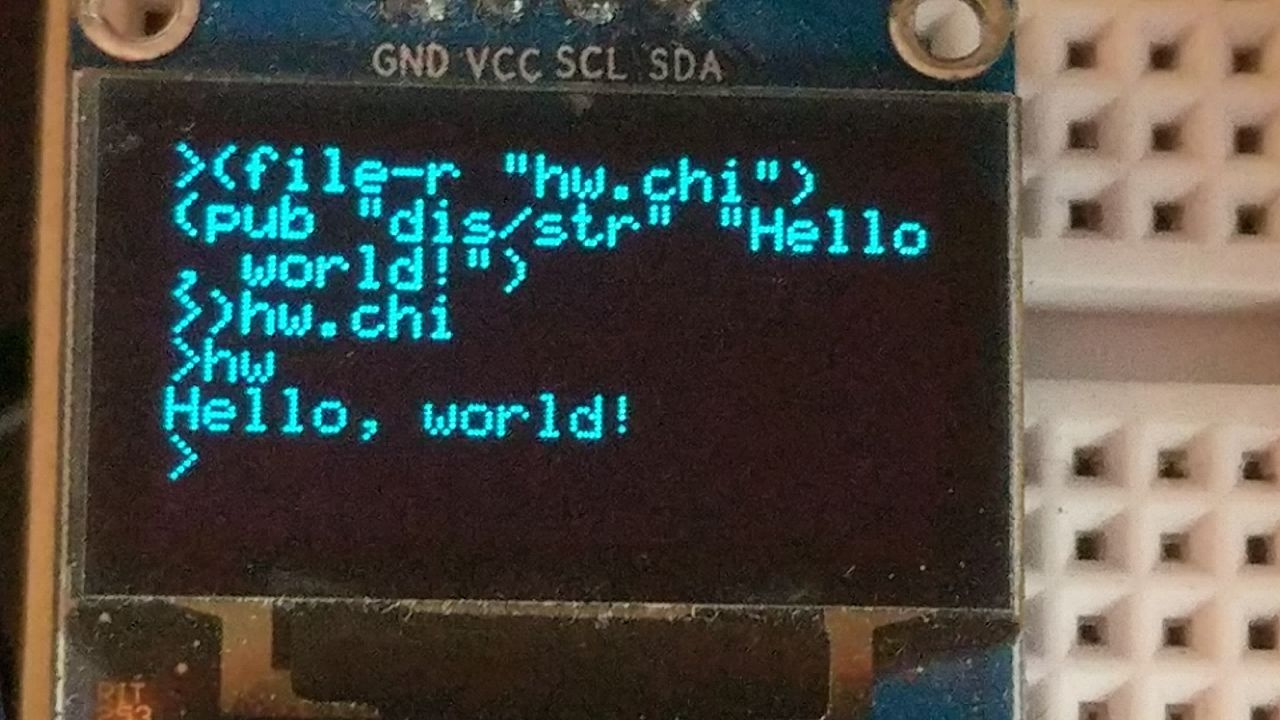
An example of this architecture, loading two programs and two drivers (also programs) all written in Chika:
- The SSD1306 driver (emulating I²C) subscribes to messages with the topics “dis/char”, “dis/clear”, “dis/page”, &c, and displays these synchronously.
- The keypad driver uses its heartbeat to monitor an analog pin, and collects presses into ASCII characters, broadcasting “kb/char”.
- The prompt program provides a small buffer for line editing, collecting characters from its “kb/char” subscription, and emitting “prompt/input” upon submission.
- The reader program invokes the prompt program for a file path, and subscribes to its input plus keypad keys to scroll the file up and down.
Now, this is a novelty - typing characters in ASCII, waiting ~4.5s for the 128x64 OLED to be completely wiped (better to use a slave chip imo). But it works, and logic is fairly decoupled/reusable. Not only that, but the keyboard input could be from any source, such as a proper keyboard or the internet, and the programs wouldn’t bat an eye - it’s just a message to them. The future holds a personal computer middleware with an ecosystem to draw from.
My workflow can involve a lot of tests through emitting messages and checking their response, on PC, and if the virtual-machine screws up (less frequently now) I can use gdb to debug the issue. Source files on Linux can be run like executables with a !#chika shebang.
I won’t talk any more, though there’s a lot more I could say (state management, compilation, variables, syntax, native operations, core library, &c.), but for the curious I’ll answer any questions :)