This thread is to discuss the idea of incorporating the suggestion by @odin to adapt uLisp to store fixnums and other immediate values in the object cell, rather than as a tagged cell referenced by a pointer:
Proposal to store immediate values in the object cell
odin
#2
On a SAMD21 board I have:
{0}3071> (let ((arr (make-array 1000))) (dotimes (i 1000) (setf (aref arr i) i)) (room))
1021
{2051}3071>
As it happens, I ported my fixnum code to ARM earlier today, and started adapting it to the beta code as soon as I saw you’d released it. Considering it’s very likely that integers that fit inside 29 bits will be a major use case for arrays, I think this difference is … worthwhile:
{0}3071> (let ((arr (make-array 1000))) (dotimes (i 1000) (setf (aref arr i) i)) (room))
2025
{1046}3071>
It’s not quite half the memory use, but pretty damn close.
New beta version of ARM uLisp with new features for feedback
Yes, I’ve been deliberating over whether to incorporate your fixnum update, and was thinking that the small improvement in speed might not be worth the extra complexity, but this makes a good case for it - thanks!
odin
#4
I’ve worked out most of the kinks in the port (I think), and uploaded the thing to GitHub. You can also get a comparison with the code from the beta version.
There’s one remaining niggle that annoys me, which is that the way NUMHEX works is kinda problematic. I can’t really tag fixnums in the same way, so as it stands numbers written in hex simply don’t become fixnums.
Yes, NUMHEX is a bit peculiar and I’m not totally convinced it’s a good idea. What do you think?
odin
#6
I have used *print-base* and *print-radix* a few times in CL, because when you’re working with stuff where bit patterns matter it’s really annoying to use decimal, so I completely understand why it’s there. It does get a little weird when the radix is a feature of the number value itself, but both the alternatives I can think of have fairly hefty downsides, the one being printer control variables (nowadays possibly the least-used facet of CL) and the other using format and ~x all over the place.
Incidentally, I should be able to get five radix40-coded letters into a symbol immediate on ARM. Sacrificing one letter to halve the size seems like a justifiable change, would you agree?
Yes, if I think that would dramatically reduce the size of most programs. Would it reduce the range of fixnums you can encode?
I would find it useful to have a description of how you’re using the bottom bits in encoding numbers vs. other types.
That’s a pity, because where NUMHEX is most useful is in lists of hex constants, such as character set bitmap definitions. One solution would be to halve the range of fixnums you can store, and use the spare bit as a hex flag. Bad idea.
odin
#9
The answer to the question is “no”. The basic model here is that I leave the mark bit alone but have the 2-bit set for all values that aren’t pointers. For each subsequent bit, I can split the remaining space in half. fixnum & 6 is always 2, leaving 29 bits for the number itself. (Out of 32, one goes to the GC marker, one to be marked as an immediate, and one to mark it as a fixnum.) The next division goes to the type markers for boxed objects: boxed & 14 is always 6. (This can be moved fairly easily, and the 28-bit allocation given to something else.) symbol & 30 would always be 14, giving 27 bits to represent the symbols, most of which goes to the radix40 encoding of five letters.
The numbers are a sequence formed from 2^n-2. The lowest bit I don’t care about, and then the bits are set until the highest one that isn’t used to represent an immediate value, which is unset. This way, the bit patterns never intersect. I can encode 29-bit fixnums, 27-bit symbols, and 21-bit Unicode scalar values. It’s still best not to proliferate the types. Although, come to think of it, it would be entirely possible to have, say, 16-bit immediate hexnums. Hmm.
The main issue to keep in mind is that code working with boxed values has to make absolutely sure that (uintptr_t)obj & 2 == 0 before dereferencing any pointer. Otherwise they can put the processor into fault mode.
johnsondavies
#10
I understand everything up to this point:
Don’t you just need to do cell>>3 to get the 29-bit fixnum?
21-bit Unicode scalar values.
I don’t understand this. Have you implemented this already?
giving 27 bits to represent the symbols, most of which goes to the radix40 encoding of five letters.
If you’re encoding 5 characters this way there doesn’t seem to be any point in having a separate 6-character boxed radix40 encoding. The boxed version may as well go straight to the symbol table.
My only concern is not to make it too complicated, requiring a decoding overhead (and opportunities for obscure bugs).
odin
#11
Yes. Sorry. Different numbers. The masks and numbers used to check the types are powers of two minus two is what I mean, not that fixnums are encoded by those.
I haven’t, and I’m not absolutely sure there is a point; I’m just noting the possibility. A 21-bit field is enough to encode any Unicode code point whatsoever, including those - like the emoji - that take up four bytes in UTF-8 and UTF-16.
That was my line of thinking. This would also result in an identically named symbol always being the same pointer, rather like the practice of interning symbols. That means tee gets to be a hardcoded value, not an allocated object in the workspace.
odin
#13
There’s no way to force unequal pointers inside uLisp, but that’s because the reader always searches through the workspace for a symbol object with the same name. The C code can break that assumption, though I’m not at all sure it ever does.
johnsondavies
#14
On 32-bit platforms allocating 27 bits for five radix-40 character symbols leaves plenty of numbers for pointers to the symbol table, so there’s no need for the boxed symbols at all. Likewise we can probably dispense with boxed characters and streams (which currently only use 16 bits). Which only leaves floats, integers > 29 bits, and strings.
johnsondavies
#15
@odin To help me visualise your original proposals, and discuss how the other types could be fitted in, I’ve drawn this diagram of the cell layouts:
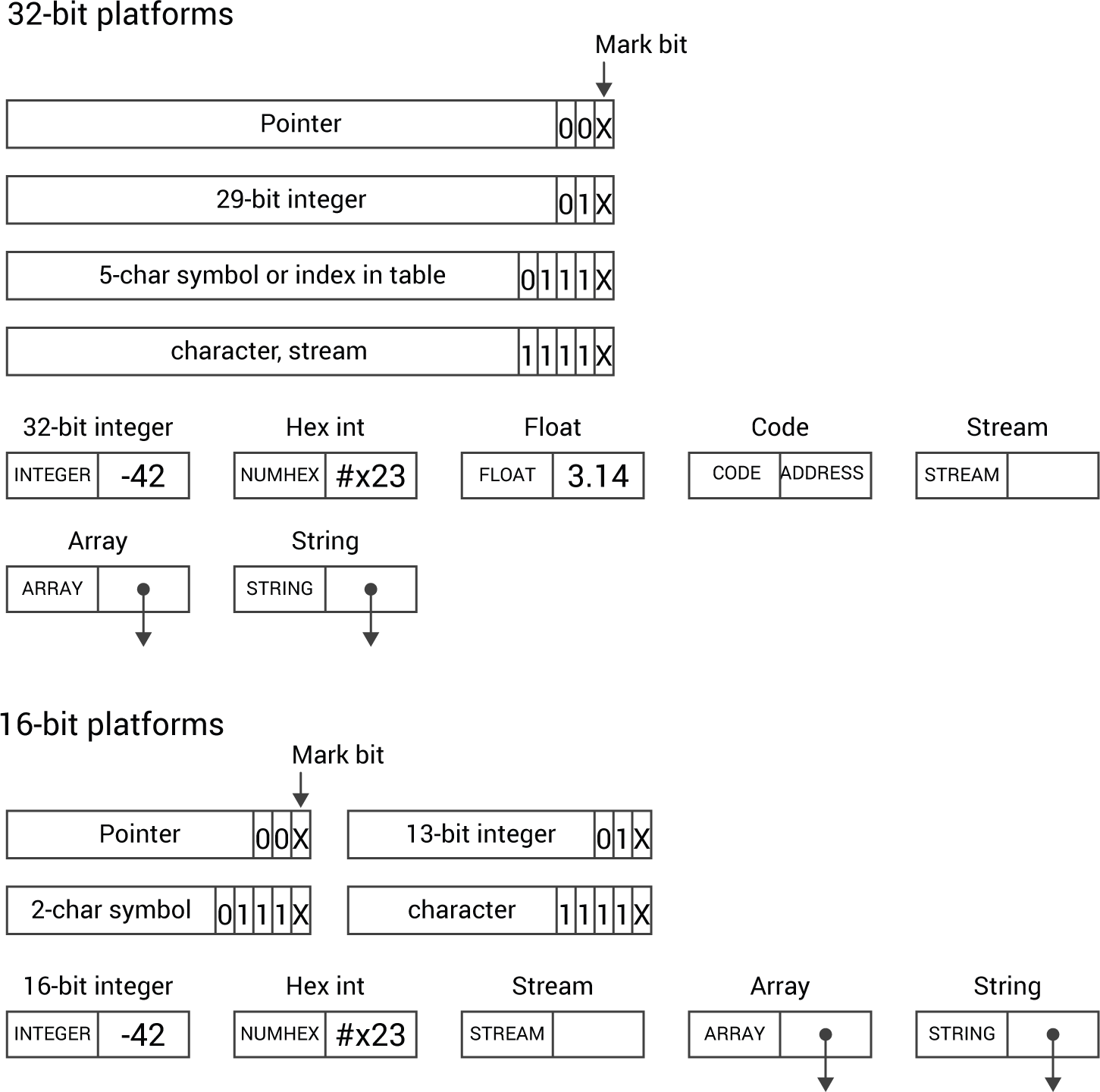
Does this agree with what you proposed?
The only loose ends are:
-
Do we need a type for symbols, or can they be fitted in the immediate cell either radix-encoded or as an index to the symbol table?
-
How should streams be represented? For consistency between 16-bit and 32-bit platforms it is probably easier to keep them as a separate type.
-
How to deal with NUMHEX - tricky one that.
odin
#16
Yes, except the 16-bit picture should say 13-bit integer.
I can basically take the symbol_t values that are currently stored in the cdr cell and put them into an immediate value. That would account for the built-ins and the symbol table in the exact same way as is done now.
It would be possible to have them immediate on 32-bit systems and boxed on 16-bit systems. Another possibility would be to say that it’s unlikely any system will have both 256 different types of streams and 256 streams of a single type, and pack them a little tighter.
But I think in the grand scheme it’s not worth it. Yes, it wastes a word or so for each stream in memory, but you’re far less likely to have many of them than you are integers or symbols.
Yeah, and I’m getting more inclined to think it needs to go away. Try this, for example: (format nil "~d" #x20). It’s an edge case that’s easy to forget.
odin
#17
I’ve added 21-bit character immediates to my GitHub branch. That was simpler than expected. Because of code-char and char-code, I also added a syntax for entering arbitrary Unicode code points using #\U+ and a hex value. None of these does proper bounds checking, which would be needed for proper Unicode support. (It’s easy to trigger silent truncation.) That would also require the reader and printer to do UTF-8, which is a larger task than updating the character functions, however.
johnsondavies
#18
Although that case could be fixed (by giving format its own number printing routine) I agree its a bit of an idiosyncrasy, and its not standard Common Lisp, so I’m happy to get rid of it.
johnsondavies
#19
That’s great, but I can’t see what the application would be, given that strings aren’t Unicode. Isn’t it going to create an expectation that uLisp is Unicode?